


Are you eager to learn how to utilize Python to log Gmail inbox metadata with Gmail Logger? This comprehensive guide will walk you through the step-by-step process of harnessing Gmail Logger’s capabilities, empowering you to streamline your email workflows, extract valuable insights, and unlock the full potential of email logging using Python. Discover the essential techniques and best practices that will enable you to seamlessly integrate Gmail Logger into your Python projects and revolutionize your email management experience.
What is Gmail Logger?
Gmail Logger is a powerful Python script developed to log Gmail inbox metadata. Gmail Logger consists of the imap_inbox_check.py Python script that retrieves metadata about messages in a Gmail inbox, grouping them by thread. The script utilizes the imaplib library to connect to Gmail’s IMAP server and retrieve information. The log_inbox.py Python script checks the state of a Gmail inbox, logs the number of threads to a tab-separated file, and saves summary information about the threads to a JSON file.
How to Set Up Gmail Logger
To get started with Gmail Logger and begin logging your Gmail inbox metadata, you’ll need to go through a setup process that involves installing the necessary dependencies and configuring access for your Gmail account. Let’s dive into the steps:
How to Install the Required Dependencies for Gmail Logger
Before you can use Gmail Logger, ensure that you have the required dependencies installed on your system. These dependencies include Git, Python, and creating an app password for your Google (Gmail) account. Here’s an overview of the installation steps:
How to Install Git for Windows
- Download Git for Windows from the official website: https://git-scm.com/download/win
- Select the 32-bit or 64-bit Git for Windows Setup
- Once the download is complete, locate the downloaded file (typically named “Git-x.y.z-64-bit.exe,” where “x.y.z” represents the version number).
- Double-click on the installer file to launch the Git for Windows setup wizard.
- In the setup wizard, you’ll see several configuration options. You can leave most of them as the default settings, but you might want to pay attention to a few:
- Select the installation location. The default location should be fine for most users.
- Choose the components to install. By default, all components are selected, and it’s recommended to keep them selected.
- Select the default editor. The default option is typically “Use Vim (the ubiquitous text editor),” but you can choose a different editor if you prefer.
- Adjusting other settings, such as the PATH environment variable or line ending conversions, is usually not necessary unless you have specific requirements.
- Once you have reviewed the settings, click “Next” to proceed.
- On the following screen, you’ll have the option to choose the SSH executable. The default option, “Use OpenSSH,” is recommended.
- Select the desired line ending conversion behavior. The default option, “Checkout Windows-style, commit Unix-style line endings,” is generally a good choice for Windows users.
- Choose the terminal emulator for Git Bash. The default option, “Use MinTTY,” is recommended.
- After making your selections, click “Next” to proceed.
- On the next screen, you can choose the default behavior of the Git Credential Manager. The default option, “Use Git’s Credential Manager,” is recommended.
- Proceed by clicking “Next” again.
- On the following screen, you can select the additional icons to be displayed on the desktop and in the Start menu. Keep the default selections or adjust them according to your preferences.
- Click “Next” to proceed.
- Finally, click on the “Install” button to start the installation process.
- Wait for the installation to complete. This might take a few moments.
- Once the installation is finished, you can leave the “Launch Git Bash” option checked if you want to start Git Bash immediately. Otherwise, you can uncheck it.
- Click “Finish” to exit the setup wizard.
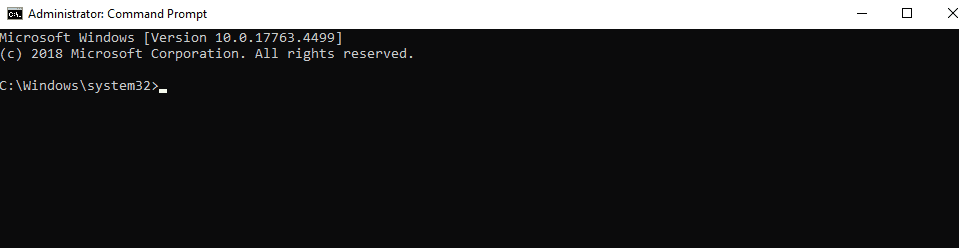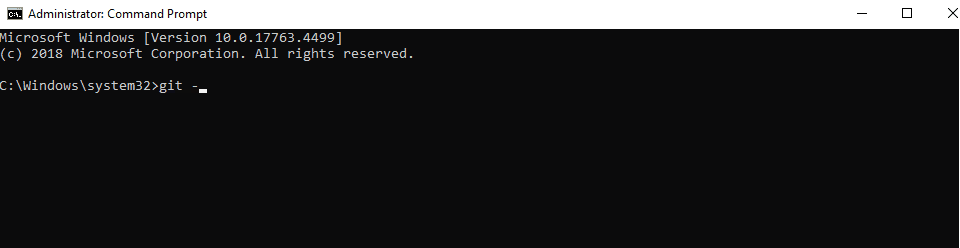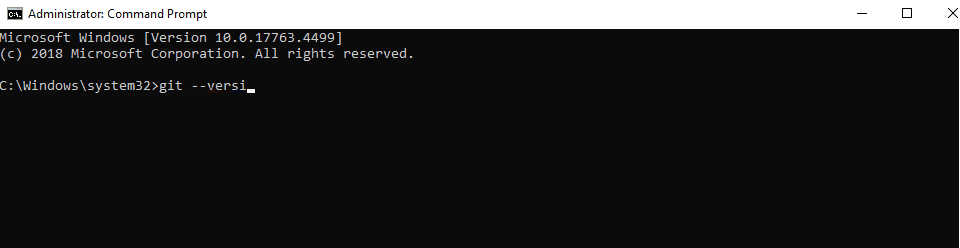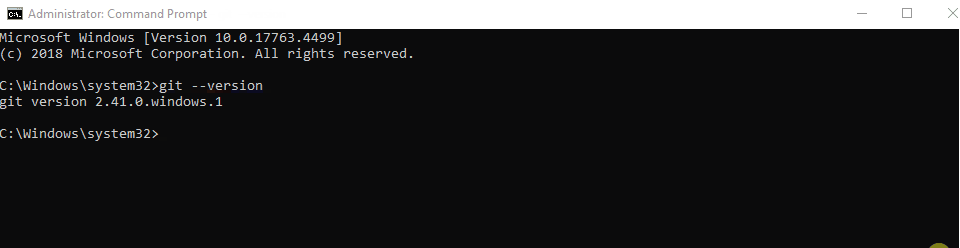
- To verify that Git is installed correctly, open the Command Prompt by pressing the Windows key, typing “cmd,” and selecting the “Command Prompt” app.
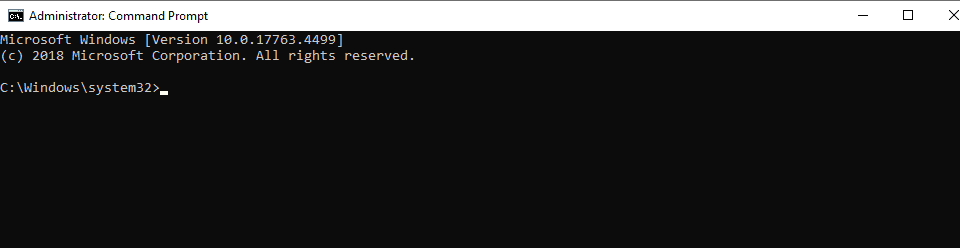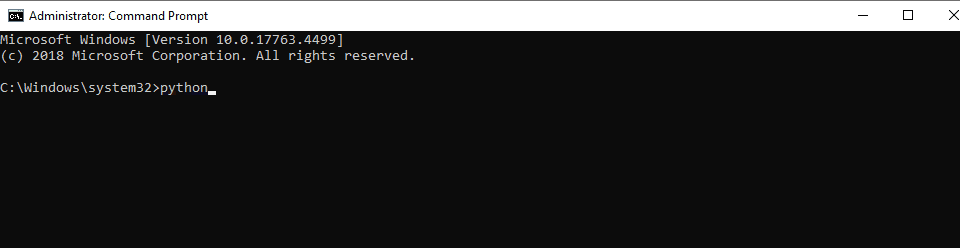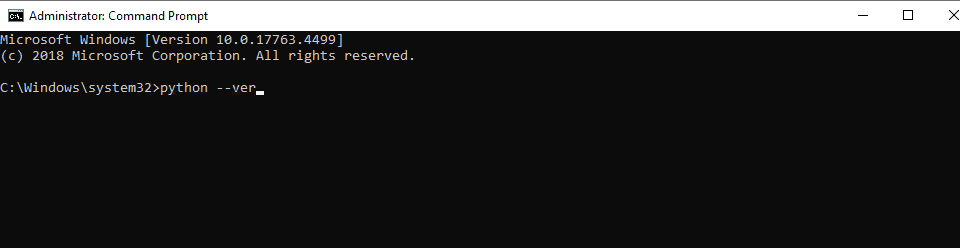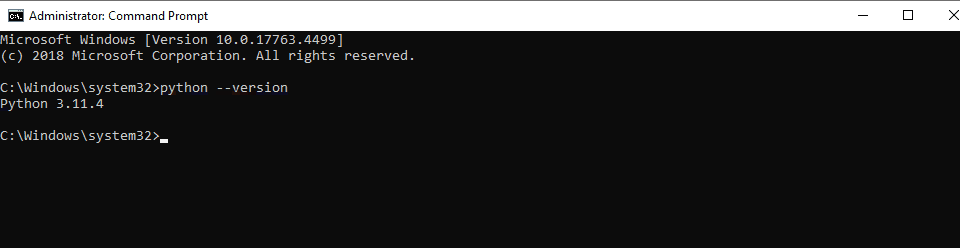
- In the Command Prompt, type
git --versionand press Enter. You should see the version number of Git installed.
How to Install Python for Windows
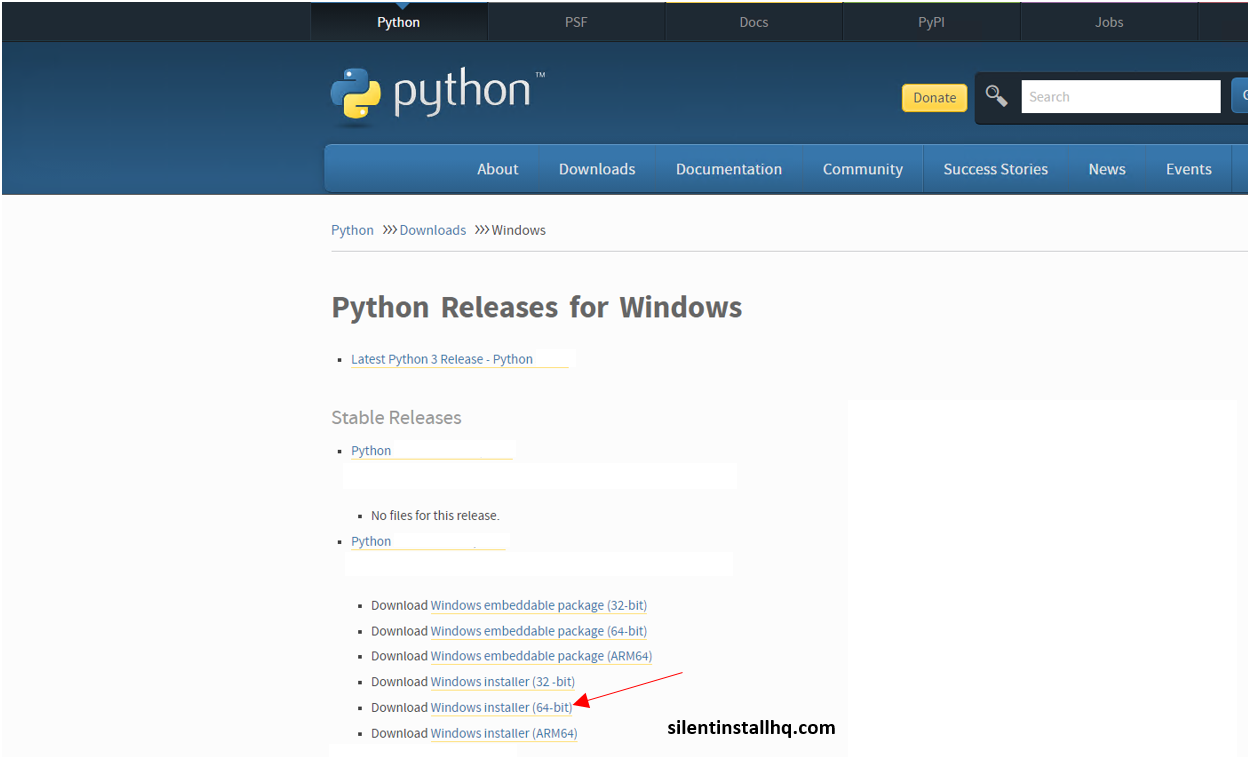
- Download Python from the official website: https://www.python.org/downloads/windows/
- Click on the link to download the Windows installer appropriate for your system. Choose the version based on whether your operating system is 32-bit or 64-bit.
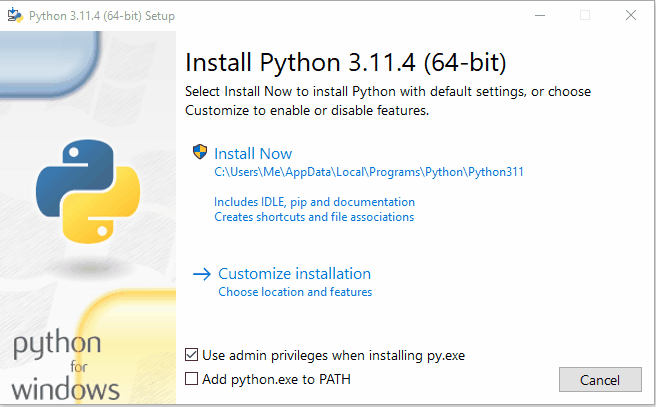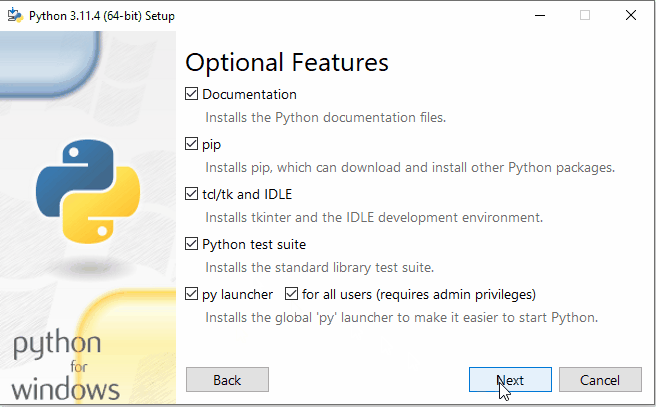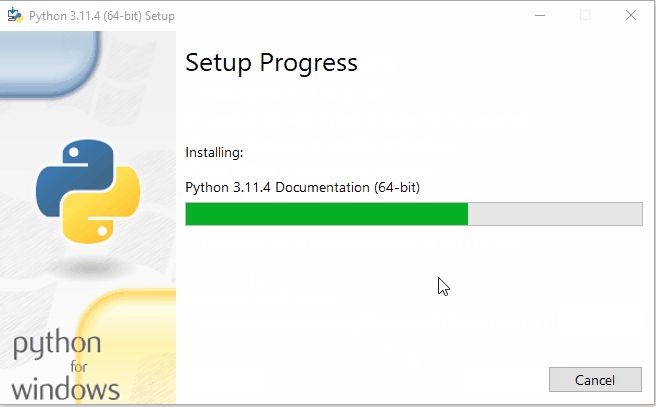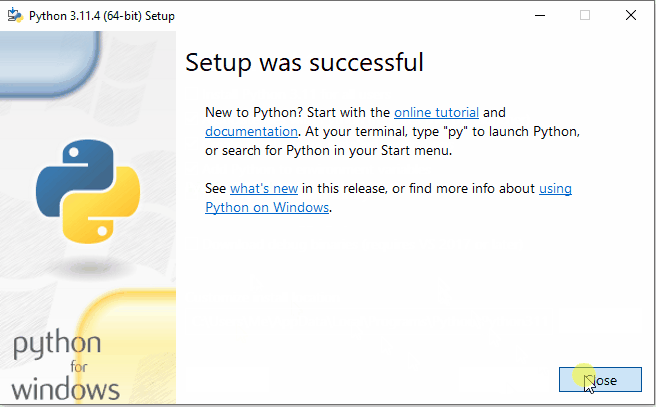
- Once the installer is downloaded, double-click on it to run the installer.
- In the Python Installer, make sure to check the box that says “Add Python to PATH” and then click on the “Customize installation” button. This will ensure that Python is added to the system’s PATH environment variable, allowing you to run Python from any command prompt.
- In the customization options, you can choose the components you want to install. It is recommended to leave the default options selected.
- On the next screen, you can choose the installation directory for Python. The default location is usually fine, but you can choose a different location if desired.
- After selecting the installation directory, click on the “Install” button to begin the installation process.
- The installer will now install Python and its associated components. This may take a few minutes.
- Once the installation is complete, click on the “Close” button to exit the installer.
- To verify that Python is installed correctly, open the Command Prompt by pressing the Windows key, typing “cmd,” and selecting the “Command Prompt” app.
- In the Command Prompt, type
python --versionand press Enter. You should see the version number of Python installed.
How to Clone the Gmail Logger Github Repository
- Open Git Bash on your computer. This was installed earlier with the Git for Windows installation.
-
Navigate to the directory where you want to clone the repository. You can use the
cdcommand to change directories. For example, if you want to clone the repository into your “Documents” folder, you can use the following command:
cd Documents
- Go to https://github.com/mddub/gmail-logger in your web browser
- Click Code & copy the repository’s URL. It should be
https://github.com/mddub/gmail-logger.git -
In Git Bash, use the
git clonecommand followed by the repository URL. For example, the repository URL ishttps://github.com/mddub/gmail-logger.git, so you would run the following command:
git clone https://github.com/mddub/gmail-logger.git
- Press Enter to execute the command. Git Bash will start cloning the repository to your local machine. The progress will be displayed in the console.
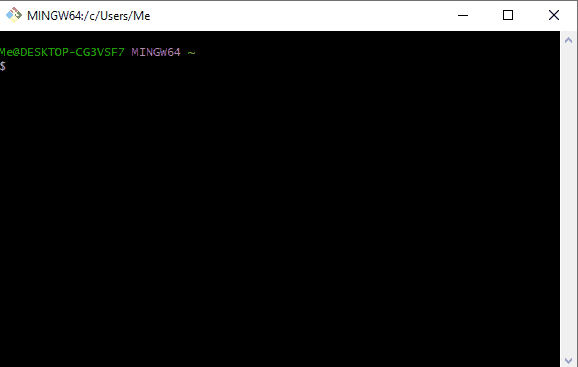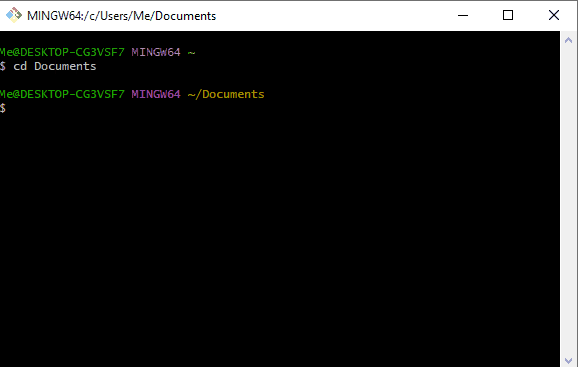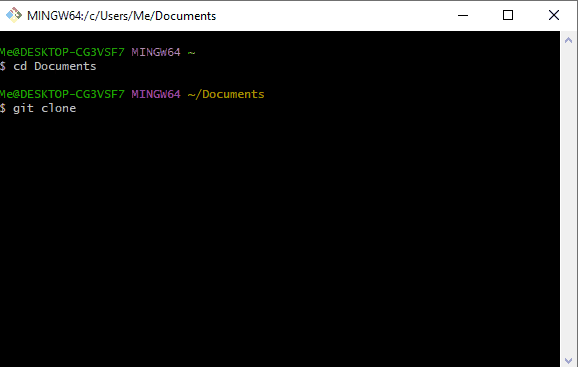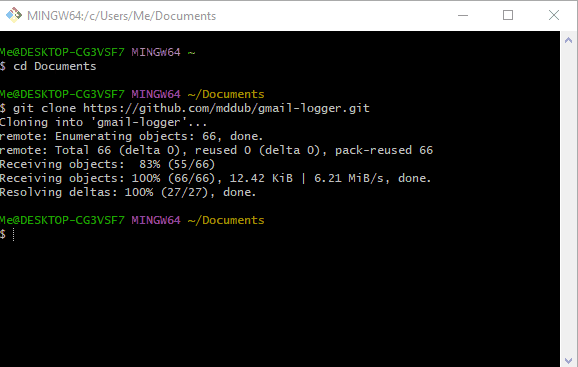
- Once the cloning process is complete, you will have a local copy of the repository in the current directory.
How to Create an App Password for your Google (Gmail) Account
- If your Google account has 2-Step Verification turned on, you will need to create a new app password for Gmail Logger to work.
- An app password is a 16-digit passcode that gives a less secure app or device permission to access your Google Account. Google Account App passwords can only be used with accounts that have 2-Step Verification turned on.
- Go to your Google Account
- Select Security
- Under “Signing in to Google,” select 2-Step Verification
- At the bottom of the page, select App passwords
- Enter a name that helps you remember where you’ll use the app password
- Select Generate
- The app password is the 16-character code that generates on your device.
- Select Done.
- (Copy the password to the secret.py file in the next step)
How to Create the secret.py File
- Add a file called secret.py which will contain your gmail email address & the password generated in the previous step
email = 'your-email@gmail.com' password = 'your-app-password'
- Copy the secret.py file to the gmail-logger directory that was created earlier.
How to Update the imap_inbox_check.py to Work with Python 3
Gmail Logger was originally written for Python 2 so we need to update the scripts to work with Python 3
- Replace the contents of the imap_inbox_check.py with the following code:
"""Get metadata about messages in a Gmail inbox, grouped by thread.
"""
import imaplib
import re
from collections import defaultdict
from dateutil.parser import parser
from dateutil.tz import tzlocal
from email.parser import HeaderParser
from functools import partial
message_index_re = re.compile('^(\d+) \(')
thread_id_re = re.compile('X-GM-THRID (\d+)')
date_parser = parser()
header_parser = HeaderParser()
def message_info_from_tuple(unread_indices, m):
parsed_headers = header_parser.parsestr(m[1].decode('utf-8'))
parsed_lowercase_headers = { k.lower() : parsed_headers[k] for k in list(parsed_headers.keys()) }
return {
'thread_id': thread_id_re.search(m[0].decode('utf-8')).group(1),
'unread': message_index_re.search(m[0].decode('utf-8')).group(1) in unread_indices,
'date': parsed_lowercase_headers['date'],
'subject': parsed_lowercase_headers.get('subject', ''),
'from': parsed_lowercase_headers.get('from', '')
}
def parse_date_from_message_dict(info):
date = info['date']
try:
parsed = date_parser.parse(date)
except ValueError:
# e.g. "Fri, 15 Apr 2016 02:45:07 -0700 (GMT-07:00)"
parsed = date_parser.parse(re.sub('\([^)]+\)', '', date))
if parsed.tzinfo is None:
# dateutil doesn't understand these...
unfortunate_tz_strings = [('EST', '-0500'), ('EDT', '-0400'), ('(GMT+00:00)', '(GMT)')]
for tz_str, offset in unfortunate_tz_strings:
date = date.replace(tz_str, offset)
parsed = date_parser.parse(date)
# Parsed dates are used for sorting, but not in the output,
# so we can afford to be lenient with bad timezones.
if parsed.tzinfo is None:
parsed = parsed.replace(tzinfo=tzlocal())
return parsed
def gmail_thread_info(email, password):
mail = imaplib.IMAP4_SSL('imap.gmail.com')
mail.login(email, password)
mail.select('INBOX')
_, (uid_list,) = mail.uid('search', None, 'ALL')
if uid_list == '':
return []
uids = uid_list.decode('utf-8').split(' ')
_, inbox = mail.uid('fetch', ','.join(uids), '(X-GM-THRID BODY.PEEK[HEADER])')
_, (unread_indices,) = mail.search(None, '(UNSEEN)')
unread_indices = unread_indices.decode('utf-8').split(' ')
# every other "message" is the string ")"
actual_messages = [inbox[i] for i in range(0, len(inbox), 2)]
thread_infos = list(map(partial(message_info_from_tuple, unread_indices), actual_messages))
# Group messages into Gmail threads
thread_id_to_messages = defaultdict(list)
for m in thread_infos:
thread_id_to_messages[m['thread_id']].append(m)
# Summarize each thread
summarized_threads = []
for thread_id, messages in thread_id_to_messages.items():
sorted_by_date = list(sorted(messages, key=parse_date_from_message_dict))
summarized_threads.append({
# Take subject from the earliest message, which is least likely to have "Re:" in it
'subject': sorted_by_date[0]['subject'],
# Take date from the latest message
'date': sorted_by_date[-1]['date'],
'from': list(set(m['from'] for m in sorted_by_date)),
'unread': any(m['unread'] for m in sorted_by_date),
'thread_id': thread_id,
})
# Sort by timestamp
return list(sorted(summarized_threads, key=parse_date_from_message_dict, reverse=True))
How to Update the log_inbox.py to Work with Python 3
Gmail Logger was originally written for Python 2 so we need to update the scripts to work with Python 3
- Replace the contents of the log_inbox.py with the following code:
"""Check the state of a Gmail inbox, then log the number of threads to a
tab-separated file, and summary information about the threads to a JSON file.
"""
from datetime import datetime
import simplejson as json
import secret
from imap_inbox_check import gmail_thread_info
LOG_FILE = 'inbox_count.log'
log_date = lambda d: d.strftime('%Y-%m-%d %H:%M:%S')
json_file_date = lambda d: d.strftime('%Y-%m-%d_%H.%M.%S')
unix_date = lambda d: str(int(d.timestamp()))
now = datetime.now()
info = gmail_thread_info(secret.email, secret.password)
log_line = '%s\t%s\t%s' % (unix_date(now), log_date(now), len(info))
print(log_line)
with open(LOG_FILE, 'a') as f:
f.write(log_line + '\n')
with open(json_file_date(now) + '.json', 'w') as f:
f.write(json.dumps(info))
How to Verify Python Package Manager (pip) is Installed & Up-to-Date
- Open an Elevated Command Prompt by Right-Clicking on Command Prompt and select Run as Administrator
- Change the Directory to the C:\Users\%Username%\Documents\gmail-logger folder
- To verify that pip is installed & up-to-date, enter the following command:
pip install --upgrade pip
- Enter the following command to see the pip version number installed:
pip --version
How to Install Virtualenv using pip
- Enter the following command to download and install Virtualenv and its dependencies.
pip install virtualenv
- Once the installation is complete, you can create a new virtual environment. Navigate to the directory where you want to create the virtual environment and run the following command:
virtualenv env
- This command will create a new directory called “env” and set up a virtual environment within it.
- Now we can Activate the virtual environment by entering the following command:
env\Scripts\activate
- After activation, you will see the name of your virtual environment displayed in the terminal or command prompt.
- Your virtual environment is now active, and any packages you install using pip will be isolated within it.
- Now we can install the Gmail Logger requirements by running the following command:
pip install -r requirements.txt
- These packages will only be available within the virtual environment.
How to Update the parser.py to Work with Python 3
Gmail Logger was originally written for Python 2 so we need to update the scripts to work with Python 3
- Replace the contents of the parser.py with the following code:
# -*- coding:iso-8859-1 -*-
"""
Copyright (c) 2003-2007 Gustavo Niemeyer <gustavo@niemeyer.net>
This module offers extensions to the standard python 2.3+
datetime module.
"""
__author__ = "Gustavo Niemeyer <gustavo@niemeyer.net>"
__license__ = "PSF License"
import datetime
import string
import time
import sys
import os
try:
from io import StringIO
except ImportError:
from io import StringIO
from . import relativedelta
from . import tz
__all__ = ["parse", "parserinfo"]
# Some pointers:
#
# http://www.cl.cam.ac.uk/~mgk25/iso-time.html
# http://www.iso.ch/iso/en/prods-services/popstds/datesandtime.html
# http://www.w3.org/TR/NOTE-datetime
# http://ringmaster.arc.nasa.gov/tools/time_formats.html
# http://search.cpan.org/author/MUIR/Time-modules-2003.0211/lib/Time/ParseDate.pm
# http://stein.cshl.org/jade/distrib/docs/java.text.SimpleDateFormat.html
class _timelex(object):
def __init__(self, instream):
if isinstance(instream, str):
instream = StringIO(instream)
self.instream = instream
self.wordchars = ('abcdfeghijklmnopqrstuvwxyz'
'ABCDEFGHIJKLMNOPQRSTUVWXYZ_'
'ßàáâãäåæçèéêëìíîïðñòóôõöøùúûüýþÿ'
'ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖØÙÚÛÜÝÞ')
self.numchars = '0123456789'
self.whitespace = ' \t\r\n'
self.charstack = []
self.tokenstack = []
self.eof = False
def get_token(self):
if self.tokenstack:
return self.tokenstack.pop(0)
seenletters = False
token = None
state = None
wordchars = self.wordchars
numchars = self.numchars
whitespace = self.whitespace
while not self.eof:
if self.charstack:
nextchar = self.charstack.pop(0)
else:
nextchar = self.instream.read(1)
while nextchar == '\x00':
nextchar = self.instream.read(1)
if not nextchar:
self.eof = True
break
elif not state:
token = nextchar
if nextchar in wordchars:
state = 'a'
elif nextchar in numchars:
state = '0'
elif nextchar in whitespace:
token = ' '
break # emit token
else:
break # emit token
elif state == 'a':
seenletters = True
if nextchar in wordchars:
token += nextchar
elif nextchar == '.':
token += nextchar
state = 'a.'
else:
self.charstack.append(nextchar)
break # emit token
elif state == '0':
if nextchar in numchars:
token += nextchar
elif nextchar == '.':
token += nextchar
state = '0.'
else:
self.charstack.append(nextchar)
break # emit token
elif state == 'a.':
seenletters = True
if nextchar == '.' or nextchar in wordchars:
token += nextchar
elif nextchar in numchars and token[-1] == '.':
token += nextchar
state = '0.'
else:
self.charstack.append(nextchar)
break # emit token
elif state == '0.':
if nextchar == '.' or nextchar in numchars:
token += nextchar
elif nextchar in wordchars and token[-1] == '.':
token += nextchar
state = 'a.'
else:
self.charstack.append(nextchar)
break # emit token
if (state in ('a.', '0.') and
(seenletters or token.count('.') > 1 or token[-1] == '.')):
l = token.split('.')
token = l[0]
for tok in l[1:]:
self.tokenstack.append('.')
if tok:
self.tokenstack.append(tok)
return token
def __iter__(self):
return self
def __next__(self):
token = self.get_token()
if token is None:
raise StopIteration
return token
def split(cls, s):
return list(cls(s))
split = classmethod(split)
class _resultbase(object):
def __init__(self):
for attr in self.__slots__:
setattr(self, attr, None)
def _repr(self, classname):
l = []
for attr in self.__slots__:
value = getattr(self, attr)
if value is not None:
l.append("%s=%s" % (attr, repr(value)))
return "%s(%s)" % (classname, ", ".join(l))
def __repr__(self):
return self._repr(self.__class__.__name__)
class parserinfo(object):
# m from a.m/p.m, t from ISO T separator
JUMP = [" ", ".", ",", ";", "-", "/", "'",
"at", "on", "and", "ad", "m", "t", "of",
"st", "nd", "rd", "th"]
WEEKDAYS = [("Mon", "Monday"),
("Tue", "Tuesday"),
("Wed", "Wednesday"),
("Thu", "Thursday"),
("Fri", "Friday"),
("Sat", "Saturday"),
("Sun", "Sunday")]
MONTHS = [("Jan", "January"),
("Feb", "February"),
("Mar", "March"),
("Apr", "April"),
("May", "May"),
("Jun", "June"),
("Jul", "July"),
("Aug", "August"),
("Sep", "September"),
("Oct", "October"),
("Nov", "November"),
("Dec", "December")]
HMS = [("h", "hour", "hours"),
("m", "minute", "minutes"),
("s", "second", "seconds")]
AMPM = [("am", "a"),
("pm", "p")]
UTCZONE = ["UTC", "GMT", "Z"]
PERTAIN = ["of"]
TZOFFSET = {}
def __init__(self, dayfirst=False, yearfirst=False):
self._jump = self._convert(self.JUMP)
self._weekdays = self._convert(self.WEEKDAYS)
self._months = self._convert(self.MONTHS)
self._hms = self._convert(self.HMS)
self._ampm = self._convert(self.AMPM)
self._utczone = self._convert(self.UTCZONE)
self._pertain = self._convert(self.PERTAIN)
self.dayfirst = dayfirst
self.yearfirst = yearfirst
self._year = time.localtime().tm_year
self._century = self._year//100*100
def _convert(self, lst):
dct = {}
for i in range(len(lst)):
v = lst[i]
if isinstance(v, tuple):
for v in v:
dct[v.lower()] = i
else:
dct[v.lower()] = i
return dct
def jump(self, name):
return name.lower() in self._jump
def weekday(self, name):
if len(name) >= 3:
try:
return self._weekdays[name.lower()]
except KeyError:
pass
return None
def month(self, name):
if len(name) >= 3:
try:
return self._months[name.lower()]+1
except KeyError:
pass
return None
def hms(self, name):
try:
return self._hms[name.lower()]
except KeyError:
return None
def ampm(self, name):
try:
return self._ampm[name.lower()]
except KeyError:
return None
def pertain(self, name):
return name.lower() in self._pertain
def utczone(self, name):
return name.lower() in self._utczone
def tzoffset(self, name):
if name in self._utczone:
return 0
return self.TZOFFSET.get(name)
def convertyear(self, year):
if year < 100:
year += self._century
if abs(year-self._year) >= 50:
if year < self._year:
year += 100
else:
year -= 100
return year
def validate(self, res):
# move to info
if res.year is not None:
res.year = self.convertyear(res.year)
if res.tzoffset == 0 and not res.tzname or res.tzname == 'Z':
res.tzname = "UTC"
res.tzoffset = 0
elif res.tzoffset != 0 and res.tzname and self.utczone(res.tzname):
res.tzoffset = 0
return True
class parser(object):
def __init__(self, info=None):
self.info = info or parserinfo()
def parse(self, timestr, default=None,
ignoretz=False, tzinfos=None,
**kwargs):
if not default:
default = datetime.datetime.now().replace(hour=0, minute=0,
second=0, microsecond=0)
res = self._parse(timestr, **kwargs)
if res is None:
raise ValueError("unknown string format")
repl = {}
for attr in ["year", "month", "day", "hour",
"minute", "second", "microsecond"]:
value = getattr(res, attr)
if value is not None:
repl[attr] = value
ret = default.replace(**repl)
if res.weekday is not None and not res.day:
ret = ret+relativedelta.relativedelta(weekday=res.weekday)
if not ignoretz:
if callable(tzinfos) or tzinfos and res.tzname in tzinfos:
if callable(tzinfos):
tzdata = tzinfos(res.tzname, res.tzoffset)
else:
tzdata = tzinfos.get(res.tzname)
if isinstance(tzdata, datetime.tzinfo):
tzinfo = tzdata
elif isinstance(tzdata, str):
tzinfo = tz.tzstr(tzdata)
elif isinstance(tzdata, int):
tzinfo = tz.tzoffset(res.tzname, tzdata)
else:
raise ValueError("offset must be tzinfo subclass, " \
"tz string, or int offset")
ret = ret.replace(tzinfo=tzinfo)
elif res.tzname and res.tzname in time.tzname:
ret = ret.replace(tzinfo=tz.tzlocal())
elif res.tzoffset == 0:
ret = ret.replace(tzinfo=tz.tzutc())
elif res.tzoffset:
ret = ret.replace(tzinfo=tz.tzoffset(res.tzname, res.tzoffset))
return ret
class _result(_resultbase):
__slots__ = ["year", "month", "day", "weekday",
"hour", "minute", "second", "microsecond",
"tzname", "tzoffset"]
def _parse(self, timestr, dayfirst=None, yearfirst=None, fuzzy=False):
info = self.info
if dayfirst is None:
dayfirst = info.dayfirst
if yearfirst is None:
yearfirst = info.yearfirst
res = self._result()
l = _timelex.split(timestr)
try:
# year/month/day list
ymd = []
# Index of the month string in ymd
mstridx = -1
len_l = len(l)
i = 0
while i < len_l:
# Check if it's a number
try:
value_repr = l[i]
value = float(value_repr)
except ValueError:
value = None
if value is not None:
# Token is a number
len_li = len(l[i])
i += 1
if (len(ymd) == 3 and len_li in (2, 4)
and (i >= len_l or (l[i] != ':' and
info.hms(l[i]) is None))):
# 19990101T23[59]
s = l[i-1]
res.hour = int(s[:2])
if len_li == 4:
res.minute = int(s[2:])
elif len_li == 6 or (len_li > 6 and l[i-1].find('.') == 6):
# YYMMDD or HHMMSS[.ss]
s = l[i-1]
if not ymd and l[i-1].find('.') == -1:
ymd.append(info.convertyear(int(s[:2])))
ymd.append(int(s[2:4]))
ymd.append(int(s[4:]))
else:
# 19990101T235959[.59]
res.hour = int(s[:2])
res.minute = int(s[2:4])
res.second, res.microsecond = _parsems(s[4:])
elif len_li == 8:
# YYYYMMDD
s = l[i-1]
ymd.append(int(s[:4]))
ymd.append(int(s[4:6]))
ymd.append(int(s[6:]))
elif len_li in (12, 14):
# YYYYMMDDhhmm[ss]
s = l[i-1]
ymd.append(int(s[:4]))
ymd.append(int(s[4:6]))
ymd.append(int(s[6:8]))
res.hour = int(s[8:10])
res.minute = int(s[10:12])
if len_li == 14:
res.second = int(s[12:])
elif ((i < len_l and info.hms(l[i]) is not None) or
(i+1 < len_l and l[i] == ' ' and
info.hms(l[i+1]) is not None)):
# HH[ ]h or MM[ ]m or SS[.ss][ ]s
if l[i] == ' ':
i += 1
idx = info.hms(l[i])
while True:
if idx == 0:
res.hour = int(value)
if value%1:
res.minute = int(60*(value%1))
elif idx == 1:
res.minute = int(value)
if value%1:
res.second = int(60*(value%1))
elif idx == 2:
res.second, res.microsecond = \
_parsems(value_repr)
i += 1
if i >= len_l or idx == 2:
break
# 12h00
try:
value_repr = l[i]
value = float(value_repr)
except ValueError:
break
else:
i += 1
idx += 1
if i < len_l:
newidx = info.hms(l[i])
if newidx is not None:
idx = newidx
elif i+1 < len_l and l[i] == ':':
# HH:MM[:SS[.ss]]
res.hour = int(value)
i += 1
value = float(l[i])
res.minute = int(value)
if value%1:
res.second = int(60*(value%1))
i += 1
if i < len_l and l[i] == ':':
res.second, res.microsecond = _parsems(l[i+1])
i += 2
elif i < len_l and l[i] in ('-', '/', '.'):
sep = l[i]
ymd.append(int(value))
i += 1
if i < len_l and not info.jump(l[i]):
try:
# 01-01[-01]
ymd.append(int(l[i]))
except ValueError:
# 01-Jan[-01]
value = info.month(l[i])
if value is not None:
ymd.append(value)
assert mstridx == -1
mstridx = len(ymd)-1
else:
return None
i += 1
if i < len_l and l[i] == sep:
# We have three members
i += 1
value = info.month(l[i])
if value is not None:
ymd.append(value)
mstridx = len(ymd)-1
assert mstridx == -1
else:
ymd.append(int(l[i]))
i += 1
elif i >= len_l or info.jump(l[i]):
if i+1 < len_l and info.ampm(l[i+1]) is not None:
# 12 am
res.hour = int(value)
if res.hour < 12 and info.ampm(l[i+1]) == 1:
res.hour += 12
elif res.hour == 12 and info.ampm(l[i+1]) == 0:
res.hour = 0
i += 1
else:
# Year, month or day
ymd.append(int(value))
i += 1
elif info.ampm(l[i]) is not None:
# 12am
res.hour = int(value)
if res.hour < 12 and info.ampm(l[i]) == 1:
res.hour += 12
elif res.hour == 12 and info.ampm(l[i]) == 0:
res.hour = 0
i += 1
elif not fuzzy:
return None
else:
i += 1
continue
# Check weekday
value = info.weekday(l[i])
if value is not None:
res.weekday = value
i += 1
continue
# Check month name
value = info.month(l[i])
if value is not None:
ymd.append(value)
assert mstridx == -1
mstridx = len(ymd)-1
i += 1
if i < len_l:
if l[i] in ('-', '/'):
# Jan-01[-99]
sep = l[i]
i += 1
ymd.append(int(l[i]))
i += 1
if i < len_l and l[i] == sep:
# Jan-01-99
i += 1
ymd.append(int(l[i]))
i += 1
elif (i+3 < len_l and l[i] == l[i+2] == ' '
and info.pertain(l[i+1])):
# Jan of 01
# In this case, 01 is clearly year
try:
value = int(l[i+3])
except ValueError:
# Wrong guess
pass
else:
# Convert it here to become unambiguous
ymd.append(info.convertyear(value))
i += 4
continue
# Check am/pm
value = info.ampm(l[i])
if value is not None:
if value == 1 and res.hour < 12:
res.hour += 12
elif value == 0 and res.hour == 12:
res.hour = 0
i += 1
continue
# Check for a timezone name
if (res.hour is not None and len(l[i]) <= 5 and
res.tzname is None and res.tzoffset is None and
not [x for x in l[i] if x not in string.ascii_uppercase]):
res.tzname = l[i]
res.tzoffset = info.tzoffset(res.tzname)
i += 1
# Check for something like GMT+3, or BRST+3. Notice
# that it doesn't mean "I am 3 hours after GMT", but
# "my time +3 is GMT". If found, we reverse the
# logic so that timezone parsing code will get it
# right.
if i < len_l and l[i] in ('+', '-'):
l[i] = ('+', '-')[l[i] == '+']
res.tzoffset = None
if info.utczone(res.tzname):
# With something like GMT+3, the timezone
# is *not* GMT.
res.tzname = None
continue
# Check for a numbered timezone
if res.hour is not None and l[i] in ('+', '-'):
signal = (-1,1)[l[i] == '+']
i += 1
len_li = len(l[i])
if len_li == 4:
# -0300
res.tzoffset = int(l[i][:2])*3600+int(l[i][2:])*60
elif i+1 < len_l and l[i+1] == ':':
# -03:00
res.tzoffset = int(l[i])*3600+int(l[i+2])*60
i += 2
elif len_li <= 2:
# -[0]3
res.tzoffset = int(l[i][:2])*3600
else:
return None
i += 1
res.tzoffset *= signal
# Look for a timezone name between parenthesis
if (i+3 < len_l and
info.jump(l[i]) and l[i+1] == '(' and l[i+3] == ')' and
3 <= len(l[i+2]) <= 5 and
not [x for x in l[i+2]
if x not in string.ascii_uppercase]):
# -0300 (BRST)
res.tzname = l[i+2]
i += 4
continue
# Check jumps
if not (info.jump(l[i]) or fuzzy):
return None
i += 1
# Process year/month/day
len_ymd = len(ymd)
if len_ymd > 3:
# More than three members!?
return None
elif len_ymd == 1 or (mstridx != -1 and len_ymd == 2):
# One member, or two members with a month string
if mstridx != -1:
res.month = ymd[mstridx]
del ymd[mstridx]
if len_ymd > 1 or mstridx == -1:
if ymd[0] > 31:
res.year = ymd[0]
else:
res.day = ymd[0]
elif len_ymd == 2:
# Two members with numbers
if ymd[0] > 31:
# 99-01
res.year, res.month = ymd
elif ymd[1] > 31:
# 01-99
res.month, res.year = ymd
elif dayfirst and ymd[1] <= 12:
# 13-01
res.day, res.month = ymd
else:
# 01-13
res.month, res.day = ymd
if len_ymd == 3:
# Three members
if mstridx == 0:
res.month, res.day, res.year = ymd
elif mstridx == 1:
if ymd[0] > 31 or (yearfirst and ymd[2] <= 31):
# 99-Jan-01
res.year, res.month, res.day = ymd
else:
# 01-Jan-01
# Give precendence to day-first, since
# two-digit years is usually hand-written.
res.day, res.month, res.year = ymd
elif mstridx == 2:
# WTF!?
if ymd[1] > 31:
# 01-99-Jan
res.day, res.year, res.month = ymd
else:
# 99-01-Jan
res.year, res.day, res.month = ymd
else:
if ymd[0] > 31 or \
(yearfirst and ymd[1] <= 12 and ymd[2] <= 31):
# 99-01-01
res.year, res.month, res.day = ymd
elif ymd[0] > 12 or (dayfirst and ymd[1] <= 12):
# 13-01-01
res.day, res.month, res.year = ymd
else:
# 01-13-01
res.month, res.day, res.year = ymd
except (IndexError, ValueError, AssertionError):
return None
if not info.validate(res):
return None
return res
DEFAULTPARSER = parser()
def parse(timestr, parserinfo=None, **kwargs):
if parserinfo:
return parser(parserinfo).parse(timestr, **kwargs)
else:
return DEFAULTPARSER.parse(timestr, **kwargs)
class _tzparser(object):
class _result(_resultbase):
__slots__ = ["stdabbr", "stdoffset", "dstabbr", "dstoffset",
"start", "end"]
class _attr(_resultbase):
__slots__ = ["month", "week", "weekday",
"yday", "jyday", "day", "time"]
def __repr__(self):
return self._repr("")
def __init__(self):
_resultbase.__init__(self)
self.start = self._attr()
self.end = self._attr()
def parse(self, tzstr):
res = self._result()
l = _timelex.split(tzstr)
try:
len_l = len(l)
i = 0
while i < len_l:
# BRST+3[BRDT[+2]]
j = i
while j < len_l and not [x for x in l[j]
if x in "0123456789:,-+"]:
j += 1
if j != i:
if not res.stdabbr:
offattr = "stdoffset"
res.stdabbr = "".join(l[i:j])
else:
offattr = "dstoffset"
res.dstabbr = "".join(l[i:j])
i = j
if (i < len_l and
(l[i] in ('+', '-') or l[i][0] in "0123456789")):
if l[i] in ('+', '-'):
# Yes, that's right. See the TZ variable
# documentation.
signal = (1,-1)[l[i] == '+']
i += 1
else:
signal = -1
len_li = len(l[i])
if len_li == 4:
# -0300
setattr(res, offattr,
(int(l[i][:2])*3600+int(l[i][2:])*60)*signal)
elif i+1 < len_l and l[i+1] == ':':
# -03:00
setattr(res, offattr,
(int(l[i])*3600+int(l[i+2])*60)*signal)
i += 2
elif len_li <= 2:
# -[0]3
setattr(res, offattr,
int(l[i][:2])*3600*signal)
else:
return None
i += 1
if res.dstabbr:
break
else:
break
if i < len_l:
for j in range(i, len_l):
if l[j] == ';': l[j] = ','
assert l[i] == ','
i += 1
if i >= len_l:
pass
elif (8 <= l.count(',') <= 9 and
not [y for x in l[i:] if x != ','
for y in x if y not in "0123456789"]):
# GMT0BST,3,0,30,3600,10,0,26,7200[,3600]
for x in (res.start, res.end):
x.month = int(l[i])
i += 2
if l[i] == '-':
value = int(l[i+1])*-1
i += 1
else:
value = int(l[i])
i += 2
if value:
x.week = value
x.weekday = (int(l[i])-1)%7
else:
x.day = int(l[i])
i += 2
x.time = int(l[i])
i += 2
if i < len_l:
if l[i] in ('-','+'):
signal = (-1,1)[l[i] == "+"]
i += 1
else:
signal = 1
res.dstoffset = (res.stdoffset+int(l[i]))*signal
elif (l.count(',') == 2 and l[i:].count('/') <= 2 and
not [y for x in l[i:] if x not in (',','/','J','M',
'.','-',':')
for y in x if y not in "0123456789"]):
for x in (res.start, res.end):
if l[i] == 'J':
# non-leap year day (1 based)
i += 1
x.jyday = int(l[i])
elif l[i] == 'M':
# month[-.]week[-.]weekday
i += 1
x.month = int(l[i])
i += 1
assert l[i] in ('-', '.')
i += 1
x.week = int(l[i])
if x.week == 5:
x.week = -1
i += 1
assert l[i] in ('-', '.')
i += 1
x.weekday = (int(l[i])-1)%7
else:
# year day (zero based)
x.yday = int(l[i])+1
i += 1
if i < len_l and l[i] == '/':
i += 1
# start time
len_li = len(l[i])
if len_li == 4:
# -0300
x.time = (int(l[i][:2])*3600+int(l[i][2:])*60)
elif i+1 < len_l and l[i+1] == ':':
# -03:00
x.time = int(l[i])*3600+int(l[i+2])*60
i += 2
if i+1 < len_l and l[i+1] == ':':
i += 2
x.time += int(l[i])
elif len_li <= 2:
# -[0]3
x.time = (int(l[i][:2])*3600)
else:
return None
i += 1
assert i == len_l or l[i] == ','
i += 1
assert i >= len_l
except (IndexError, ValueError, AssertionError):
return None
return res
DEFAULTTZPARSER = _tzparser()
def _parsetz(tzstr):
return DEFAULTTZPARSER.parse(tzstr)
def _parsems(value):
"""Parse a I[.F] seconds value into (seconds, microseconds)."""
if "." not in value:
return int(value), 0
else:
i, f = value.split(".")
return int(i), int(f.ljust(6, "0")[:6])
# vim:ts=4:sw=4:et
How to Update the relativedelta.py to Work with Python 3
Gmail Logger was originally written for Python 2 so we need to update the scripts to work with Python 3
- Replace the contents of the relativedelta.py with the following code:
"""
Copyright (c) 2003-2010 Gustavo Niemeyer <gustavo@niemeyer.net>
This module offers extensions to the standard python 2.3+
datetime module.
"""
__author__ = "Gustavo Niemeyer <gustavo@niemeyer.net>"
__license__ = "PSF License"
import datetime
import calendar
__all__ = ["relativedelta", "MO", "TU", "WE", "TH", "FR", "SA", "SU"]
class weekday(object):
__slots__ = ["weekday", "n"]
def __init__(self, weekday, n=None):
self.weekday = weekday
self.n = n
def __call__(self, n):
if n == self.n:
return self
else:
return self.__class__(self.weekday, n)
def __eq__(self, other):
try:
if self.weekday != other.weekday or self.n != other.n:
return False
except AttributeError:
return False
return True
def __repr__(self):
s = ("MO", "TU", "WE", "TH", "FR", "SA", "SU")[self.weekday]
if not self.n:
return s
else:
return "%s(%+d)" % (s, self.n)
MO, TU, WE, TH, FR, SA, SU = weekdays = tuple([weekday(x) for x in range(7)])
class relativedelta:
"""
The relativedelta type is based on the specification of the excelent
work done by M.-A. Lemburg in his mx.DateTime extension. However,
notice that this type does *NOT* implement the same algorithm as
his work. Do *NOT* expect it to behave like mx.DateTime's counterpart.
There's two different ways to build a relativedelta instance. The
first one is passing it two date/datetime classes:
relativedelta(datetime1, datetime2)
And the other way is to use the following keyword arguments:
year, month, day, hour, minute, second, microsecond:
Absolute information.
years, months, weeks, days, hours, minutes, seconds, microseconds:
Relative information, may be negative.
weekday:
One of the weekday instances (MO, TU, etc). These instances may
receive a parameter N, specifying the Nth weekday, which could
be positive or negative (like MO(+1) or MO(-2). Not specifying
it is the same as specifying +1. You can also use an integer,
where 0=MO.
leapdays:
Will add given days to the date found, if year is a leap
year, and the date found is post 28 of february.
yearday, nlyearday:
Set the yearday or the non-leap year day (jump leap days).
These are converted to day/month/leapdays information.
Here is the behavior of operations with relativedelta:
1) Calculate the absolute year, using the 'year' argument, or the
original datetime year, if the argument is not present.
2) Add the relative 'years' argument to the absolute year.
3) Do steps 1 and 2 for month/months.
4) Calculate the absolute day, using the 'day' argument, or the
original datetime day, if the argument is not present. Then,
subtract from the day until it fits in the year and month
found after their operations.
5) Add the relative 'days' argument to the absolute day. Notice
that the 'weeks' argument is multiplied by 7 and added to
'days'.
6) Do steps 1 and 2 for hour/hours, minute/minutes, second/seconds,
microsecond/microseconds.
7) If the 'weekday' argument is present, calculate the weekday,
with the given (wday, nth) tuple. wday is the index of the
weekday (0-6, 0=Mon), and nth is the number of weeks to add
forward or backward, depending on its signal. Notice that if
the calculated date is already Monday, for example, using
(0, 1) or (0, -1) won't change the day.
"""
def __init__(self, dt1=None, dt2=None,
years=0, months=0, days=0, leapdays=0, weeks=0,
hours=0, minutes=0, seconds=0, microseconds=0,
year=None, month=None, day=None, weekday=None,
yearday=None, nlyearday=None,
hour=None, minute=None, second=None, microsecond=None):
if dt1 and dt2:
if not isinstance(dt1, datetime.date) or \
not isinstance(dt2, datetime.date):
raise TypeError("relativedelta only diffs datetime/date")
if type(dt1) is not type(dt2):
if not isinstance(dt1, datetime.datetime):
dt1 = datetime.datetime.fromordinal(dt1.toordinal())
elif not isinstance(dt2, datetime.datetime):
dt2 = datetime.datetime.fromordinal(dt2.toordinal())
self.years = 0
self.months = 0
self.days = 0
self.leapdays = 0
self.hours = 0
self.minutes = 0
self.seconds = 0
self.microseconds = 0
self.year = None
self.month = None
self.day = None
self.weekday = None
self.hour = None
self.minute = None
self.second = None
self.microsecond = None
self._has_time = 0
months = (dt1.year*12+dt1.month)-(dt2.year*12+dt2.month)
self._set_months(months)
dtm = self.__radd__(dt2)
if dt1 < dt2:
while dt1 > dtm:
months += 1
self._set_months(months)
dtm = self.__radd__(dt2)
else:
while dt1 < dtm:
months -= 1
self._set_months(months)
dtm = self.__radd__(dt2)
delta = dt1 - dtm
self.seconds = delta.seconds+delta.days*86400
self.microseconds = delta.microseconds
else:
self.years = years
self.months = months
self.days = days+weeks*7
self.leapdays = leapdays
self.hours = hours
self.minutes = minutes
self.seconds = seconds
self.microseconds = microseconds
self.year = year
self.month = month
self.day = day
self.hour = hour
self.minute = minute
self.second = second
self.microsecond = microsecond
if type(weekday) is int:
self.weekday = weekdays[weekday]
else:
self.weekday = weekday
yday = 0
if nlyearday:
yday = nlyearday
elif yearday:
yday = yearday
if yearday > 59:
self.leapdays = -1
if yday:
ydayidx = [31,59,90,120,151,181,212,243,273,304,334,366]
for idx, ydays in enumerate(ydayidx):
if yday <= ydays:
self.month = idx+1
if idx == 0:
self.day = yday
else:
self.day = yday-ydayidx[idx-1]
break
else:
raise ValueError("invalid year day (%d)" % yday)
self._fix()
def _fix(self):
if abs(self.microseconds) > 999999:
s = self.microseconds//abs(self.microseconds)
div, mod = divmod(self.microseconds*s, 1000000)
self.microseconds = mod*s
self.seconds += div*s
if abs(self.seconds) > 59:
s = self.seconds//abs(self.seconds)
div, mod = divmod(self.seconds*s, 60)
self.seconds = mod*s
self.minutes += div*s
if abs(self.minutes) > 59:
s = self.minutes//abs(self.minutes)
div, mod = divmod(self.minutes*s, 60)
self.minutes = mod*s
self.hours += div*s
if abs(self.hours) > 23:
s = self.hours//abs(self.hours)
div, mod = divmod(self.hours*s, 24)
self.hours = mod*s
self.days += div*s
if abs(self.months) > 11:
s = self.months//abs(self.months)
div, mod = divmod(self.months*s, 12)
self.months = mod*s
self.years += div*s
if (self.hours or self.minutes or self.seconds or self.microseconds or
self.hour is not None or self.minute is not None or
self.second is not None or self.microsecond is not None):
self._has_time = 1
else:
self._has_time = 0
def _set_months(self, months):
self.months = months
if abs(self.months) > 11:
s = self.months//abs(self.months)
div, mod = divmod(self.months*s, 12)
self.months = mod*s
self.years = div*s
else:
self.years = 0
def __radd__(self, other):
if not isinstance(other, datetime.date):
raise TypeError("unsupported type for add operation")
elif self._has_time and not isinstance(other, datetime.datetime):
other = datetime.datetime.fromordinal(other.toordinal())
year = (self.year or other.year)+self.years
month = self.month or other.month
if self.months:
assert 1 <= abs(self.months) <= 12
month += self.months
if month > 12:
year += 1
month -= 12
elif month < 1:
year -= 1
month += 12
day = min(calendar.monthrange(year, month)[1],
self.day or other.day)
repl = {"year": year, "month": month, "day": day}
for attr in ["hour", "minute", "second", "microsecond"]:
value = getattr(self, attr)
if value is not None:
repl[attr] = value
days = self.days
if self.leapdays and month > 2 and calendar.isleap(year):
days += self.leapdays
ret = (other.replace(**repl)
+ datetime.timedelta(days=days,
hours=self.hours,
minutes=self.minutes,
seconds=self.seconds,
microseconds=self.microseconds))
if self.weekday:
weekday, nth = self.weekday.weekday, self.weekday.n or 1
jumpdays = (abs(nth)-1)*7
if nth > 0:
jumpdays += (7-ret.weekday()+weekday)%7
else:
jumpdays += (ret.weekday()-weekday)%7
jumpdays *= -1
ret += datetime.timedelta(days=jumpdays)
return ret
def __rsub__(self, other):
return self.__neg__().__radd__(other)
def __add__(self, other):
if not isinstance(other, relativedelta):
raise TypeError("unsupported type for add operation")
return relativedelta(years=other.years+self.years,
months=other.months+self.months,
days=other.days+self.days,
hours=other.hours+self.hours,
minutes=other.minutes+self.minutes,
seconds=other.seconds+self.seconds,
microseconds=other.microseconds+self.microseconds,
leapdays=other.leapdays or self.leapdays,
year=other.year or self.year,
month=other.month or self.month,
day=other.day or self.day,
weekday=other.weekday or self.weekday,
hour=other.hour or self.hour,
minute=other.minute or self.minute,
second=other.second or self.second,
microsecond=other.second or self.microsecond)
def __sub__(self, other):
if not isinstance(other, relativedelta):
raise TypeError("unsupported type for sub operation")
return relativedelta(years=other.years-self.years,
months=other.months-self.months,
days=other.days-self.days,
hours=other.hours-self.hours,
minutes=other.minutes-self.minutes,
seconds=other.seconds-self.seconds,
microseconds=other.microseconds-self.microseconds,
leapdays=other.leapdays or self.leapdays,
year=other.year or self.year,
month=other.month or self.month,
day=other.day or self.day,
weekday=other.weekday or self.weekday,
hour=other.hour or self.hour,
minute=other.minute or self.minute,
second=other.second or self.second,
microsecond=other.second or self.microsecond)
def __neg__(self):
return relativedelta(years=-self.years,
months=-self.months,
days=-self.days,
hours=-self.hours,
minutes=-self.minutes,
seconds=-self.seconds,
microseconds=-self.microseconds,
leapdays=self.leapdays,
year=self.year,
month=self.month,
day=self.day,
weekday=self.weekday,
hour=self.hour,
minute=self.minute,
second=self.second,
microsecond=self.microsecond)
def __bool__(self):
return not (not self.years and
not self.months and
not self.days and
not self.hours and
not self.minutes and
not self.seconds and
not self.microseconds and
not self.leapdays and
self.year is None and
self.month is None and
self.day is None and
self.weekday is None and
self.hour is None and
self.minute is None and
self.second is None and
self.microsecond is None)
def __mul__(self, other):
f = float(other)
return relativedelta(years=self.years*f,
months=self.months*f,
days=self.days*f,
hours=self.hours*f,
minutes=self.minutes*f,
seconds=self.seconds*f,
microseconds=self.microseconds*f,
leapdays=self.leapdays,
year=self.year,
month=self.month,
day=self.day,
weekday=self.weekday,
hour=self.hour,
minute=self.minute,
second=self.second,
microsecond=self.microsecond)
def __eq__(self, other):
if not isinstance(other, relativedelta):
return False
if self.weekday or other.weekday:
if not self.weekday or not other.weekday:
return False
if self.weekday.weekday != other.weekday.weekday:
return False
n1, n2 = self.weekday.n, other.weekday.n
if n1 != n2 and not ((not n1 or n1 == 1) and (not n2 or n2 == 1)):
return False
return (self.years == other.years and
self.months == other.months and
self.days == other.days and
self.hours == other.hours and
self.minutes == other.minutes and
self.seconds == other.seconds and
self.leapdays == other.leapdays and
self.year == other.year and
self.month == other.month and
self.day == other.day and
self.hour == other.hour and
self.minute == other.minute and
self.second == other.second and
self.microsecond == other.microsecond)
def __ne__(self, other):
return not self.__eq__(other)
def __div__(self, other):
return self.__mul__(1/float(other))
def __repr__(self):
l = []
for attr in ["years", "months", "days", "leapdays",
"hours", "minutes", "seconds", "microseconds"]:
value = getattr(self, attr)
if value:
l.append("%s=%+d" % (attr, value))
for attr in ["year", "month", "day", "weekday",
"hour", "minute", "second", "microsecond"]:
value = getattr(self, attr)
if value is not None:
l.append("%s=%s" % (attr, repr(value)))
return "%s(%s)" % (self.__class__.__name__, ", ".join(l))
# vim:ts=4:sw=4:et
How to Update the tz.py to Work with Python 3
Gmail Logger was originally written for Python 2 so we need to update the scripts to work with Python 3
- Replace the contents of the tz.py with the following code:
"""
Copyright (c) 2003-2007 Gustavo Niemeyer <gustavo@niemeyer.net>
This module offers extensions to the standard python 2.3+
datetime module.
"""
__author__ = "Gustavo Niemeyer <gustavo@niemeyer.net>"
__license__ = "PSF License"
import datetime
import struct
import time
import sys
import os
relativedelta = None
parser = None
rrule = None
__all__ = ["tzutc", "tzoffset", "tzlocal", "tzfile", "tzrange",
"tzstr", "tzical", "tzwin", "tzwinlocal", "gettz"]
try:
from dateutil.tzwin import tzwin, tzwinlocal
except (ImportError, OSError):
tzwin, tzwinlocal = None, None
ZERO = datetime.timedelta(0)
EPOCHORDINAL = datetime.datetime.utcfromtimestamp(0).toordinal()
class tzutc(datetime.tzinfo):
def utcoffset(self, dt):
return ZERO
def dst(self, dt):
return ZERO
def tzname(self, dt):
return "UTC"
def __eq__(self, other):
return (isinstance(other, tzutc) or
(isinstance(other, tzoffset) and other._offset == ZERO))
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "%s()" % self.__class__.__name__
__reduce__ = object.__reduce__
class tzoffset(datetime.tzinfo):
def __init__(self, name, offset):
self._name = name
self._offset = datetime.timedelta(seconds=offset)
def utcoffset(self, dt):
return self._offset
def dst(self, dt):
return ZERO
def tzname(self, dt):
return self._name
def __eq__(self, other):
return (isinstance(other, tzoffset) and
self._offset == other._offset)
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "%s(%s, %s)" % (self.__class__.__name__,
repr(self._name),
self._offset.days*86400+self._offset.seconds)
__reduce__ = object.__reduce__
class tzlocal(datetime.tzinfo):
_std_offset = datetime.timedelta(seconds=-time.timezone)
if time.daylight:
_dst_offset = datetime.timedelta(seconds=-time.altzone)
else:
_dst_offset = _std_offset
def utcoffset(self, dt):
if self._isdst(dt):
return self._dst_offset
else:
return self._std_offset
def dst(self, dt):
if self._isdst(dt):
return self._dst_offset-self._std_offset
else:
return ZERO
def tzname(self, dt):
return time.tzname[self._isdst(dt)]
def _isdst(self, dt):
# We can't use mktime here. It is unstable when deciding if
# the hour near to a change is DST or not.
#
# timestamp = time.mktime((dt.year, dt.month, dt.day, dt.hour,
# dt.minute, dt.second, dt.weekday(), 0, -1))
# return time.localtime(timestamp).tm_isdst
#
# The code above yields the following result:
#
#>>> import tz, datetime
#>>> t = tz.tzlocal()
#>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
#'BRDT'
#>>> datetime.datetime(2003,2,16,0,tzinfo=t).tzname()
#'BRST'
#>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
#'BRST'
#>>> datetime.datetime(2003,2,15,22,tzinfo=t).tzname()
#'BRDT'
#>>> datetime.datetime(2003,2,15,23,tzinfo=t).tzname()
#'BRDT'
#
# Here is a more stable implementation:
#
timestamp = ((dt.toordinal() - EPOCHORDINAL) * 86400
+ dt.hour * 3600
+ dt.minute * 60
+ dt.second)
return time.localtime(timestamp+time.timezone).tm_isdst
def __eq__(self, other):
if not isinstance(other, tzlocal):
return False
return (self._std_offset == other._std_offset and
self._dst_offset == other._dst_offset)
return True
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "%s()" % self.__class__.__name__
__reduce__ = object.__reduce__
class _ttinfo(object):
__slots__ = ["offset", "delta", "isdst", "abbr", "isstd", "isgmt"]
def __init__(self):
for attr in self.__slots__:
setattr(self, attr, None)
def __repr__(self):
l = []
for attr in self.__slots__:
value = getattr(self, attr)
if value is not None:
l.append("%s=%s" % (attr, repr(value)))
return "%s(%s)" % (self.__class__.__name__, ", ".join(l))
def __eq__(self, other):
if not isinstance(other, _ttinfo):
return False
return (self.offset == other.offset and
self.delta == other.delta and
self.isdst == other.isdst and
self.abbr == other.abbr and
self.isstd == other.isstd and
self.isgmt == other.isgmt)
def __ne__(self, other):
return not self.__eq__(other)
def __getstate__(self):
state = {}
for name in self.__slots__:
state[name] = getattr(self, name, None)
return state
def __setstate__(self, state):
for name in self.__slots__:
if name in state:
setattr(self, name, state[name])
class tzfile(datetime.tzinfo):
# http://www.twinsun.com/tz/tz-link.htm
# ftp://elsie.nci.nih.gov/pub/tz*.tar.gz
def __init__(self, fileobj):
if isinstance(fileobj, str):
self._filename = fileobj
fileobj = open(fileobj)
elif hasattr(fileobj, "name"):
self._filename = fileobj.name
else:
self._filename = repr(fileobj)
# From tzfile(5):
#
# The time zone information files used by tzset(3)
# begin with the magic characters "TZif" to identify
# them as time zone information files, followed by
# sixteen bytes reserved for future use, followed by
# six four-byte values of type long, written in a
# ``standard'' byte order (the high-order byte
# of the value is written first).
if fileobj.read(4) != "TZif":
raise ValueError("magic not found")
fileobj.read(16)
(
# The number of UTC/local indicators stored in the file.
ttisgmtcnt,
# The number of standard/wall indicators stored in the file.
ttisstdcnt,
# The number of leap seconds for which data is
# stored in the file.
leapcnt,
# The number of "transition times" for which data
# is stored in the file.
timecnt,
# The number of "local time types" for which data
# is stored in the file (must not be zero).
typecnt,
# The number of characters of "time zone
# abbreviation strings" stored in the file.
charcnt,
) = struct.unpack(">6l", fileobj.read(24))
# The above header is followed by tzh_timecnt four-byte
# values of type long, sorted in ascending order.
# These values are written in ``standard'' byte order.
# Each is used as a transition time (as returned by
# time(2)) at which the rules for computing local time
# change.
if timecnt:
self._trans_list = struct.unpack(">%dl" % timecnt,
fileobj.read(timecnt*4))
else:
self._trans_list = []
# Next come tzh_timecnt one-byte values of type unsigned
# char; each one tells which of the different types of
# ``local time'' types described in the file is associated
# with the same-indexed transition time. These values
# serve as indices into an array of ttinfo structures that
# appears next in the file.
if timecnt:
self._trans_idx = struct.unpack(">%dB" % timecnt,
fileobj.read(timecnt))
else:
self._trans_idx = []
# Each ttinfo structure is written as a four-byte value
# for tt_gmtoff of type long, in a standard byte
# order, followed by a one-byte value for tt_isdst
# and a one-byte value for tt_abbrind. In each
# structure, tt_gmtoff gives the number of
# seconds to be added to UTC, tt_isdst tells whether
# tm_isdst should be set by localtime(3), and
# tt_abbrind serves as an index into the array of
# time zone abbreviation characters that follow the
# ttinfo structure(s) in the file.
ttinfo = []
for i in range(typecnt):
ttinfo.append(struct.unpack(">lbb", fileobj.read(6)))
abbr = fileobj.read(charcnt)
# Then there are tzh_leapcnt pairs of four-byte
# values, written in standard byte order; the
# first value of each pair gives the time (as
# returned by time(2)) at which a leap second
# occurs; the second gives the total number of
# leap seconds to be applied after the given time.
# The pairs of values are sorted in ascending order
# by time.
# Not used, for now
if leapcnt:
leap = struct.unpack(">%dl" % (leapcnt*2),
fileobj.read(leapcnt*8))
# Then there are tzh_ttisstdcnt standard/wall
# indicators, each stored as a one-byte value;
# they tell whether the transition times associated
# with local time types were specified as standard
# time or wall clock time, and are used when
# a time zone file is used in handling POSIX-style
# time zone environment variables.
if ttisstdcnt:
isstd = struct.unpack(">%db" % ttisstdcnt,
fileobj.read(ttisstdcnt))
# Finally, there are tzh_ttisgmtcnt UTC/local
# indicators, each stored as a one-byte value;
# they tell whether the transition times associated
# with local time types were specified as UTC or
# local time, and are used when a time zone file
# is used in handling POSIX-style time zone envi-
# ronment variables.
if ttisgmtcnt:
isgmt = struct.unpack(">%db" % ttisgmtcnt,
fileobj.read(ttisgmtcnt))
# ** Everything has been read **
# Build ttinfo list
self._ttinfo_list = []
for i in range(typecnt):
gmtoff, isdst, abbrind = ttinfo[i]
# Round to full-minutes if that's not the case. Python's
# datetime doesn't accept sub-minute timezones. Check
# http://python.org/sf/1447945 for some information.
gmtoff = (gmtoff+30)//60*60
tti = _ttinfo()
tti.offset = gmtoff
tti.delta = datetime.timedelta(seconds=gmtoff)
tti.isdst = isdst
tti.abbr = abbr[abbrind:abbr.find('\x00', abbrind)]
tti.isstd = (ttisstdcnt > i and isstd[i] != 0)
tti.isgmt = (ttisgmtcnt > i and isgmt[i] != 0)
self._ttinfo_list.append(tti)
# Replace ttinfo indexes for ttinfo objects.
trans_idx = []
for idx in self._trans_idx:
trans_idx.append(self._ttinfo_list[idx])
self._trans_idx = tuple(trans_idx)
# Set standard, dst, and before ttinfos. before will be
# used when a given time is before any transitions,
# and will be set to the first non-dst ttinfo, or to
# the first dst, if all of them are dst.
self._ttinfo_std = None
self._ttinfo_dst = None
self._ttinfo_before = None
if self._ttinfo_list:
if not self._trans_list:
self._ttinfo_std = self._ttinfo_first = self._ttinfo_list[0]
else:
for i in range(timecnt-1,-1,-1):
tti = self._trans_idx[i]
if not self._ttinfo_std and not tti.isdst:
self._ttinfo_std = tti
elif not self._ttinfo_dst and tti.isdst:
self._ttinfo_dst = tti
if self._ttinfo_std and self._ttinfo_dst:
break
else:
if self._ttinfo_dst and not self._ttinfo_std:
self._ttinfo_std = self._ttinfo_dst
for tti in self._ttinfo_list:
if not tti.isdst:
self._ttinfo_before = tti
break
else:
self._ttinfo_before = self._ttinfo_list[0]
# Now fix transition times to become relative to wall time.
#
# I'm not sure about this. In my tests, the tz source file
# is setup to wall time, and in the binary file isstd and
# isgmt are off, so it should be in wall time. OTOH, it's
# always in gmt time. Let me know if you have comments
# about this.
laststdoffset = 0
self._trans_list = list(self._trans_list)
for i in range(len(self._trans_list)):
tti = self._trans_idx[i]
if not tti.isdst:
# This is std time.
self._trans_list[i] += tti.offset
laststdoffset = tti.offset
else:
# This is dst time. Convert to std.
self._trans_list[i] += laststdoffset
self._trans_list = tuple(self._trans_list)
def _find_ttinfo(self, dt, laststd=0):
timestamp = ((dt.toordinal() - EPOCHORDINAL) * 86400
+ dt.hour * 3600
+ dt.minute * 60
+ dt.second)
idx = 0
for trans in self._trans_list:
if timestamp < trans:
break
idx += 1
else:
return self._ttinfo_std
if idx == 0:
return self._ttinfo_before
if laststd:
while idx > 0:
tti = self._trans_idx[idx-1]
if not tti.isdst:
return tti
idx -= 1
else:
return self._ttinfo_std
else:
return self._trans_idx[idx-1]
def utcoffset(self, dt):
if not self._ttinfo_std:
return ZERO
return self._find_ttinfo(dt).delta
def dst(self, dt):
if not self._ttinfo_dst:
return ZERO
tti = self._find_ttinfo(dt)
if not tti.isdst:
return ZERO
# The documentation says that utcoffset()-dst() must
# be constant for every dt.
return tti.delta-self._find_ttinfo(dt, laststd=1).delta
# An alternative for that would be:
#
# return self._ttinfo_dst.offset-self._ttinfo_std.offset
#
# However, this class stores historical changes in the
# dst offset, so I belive that this wouldn't be the right
# way to implement this.
def tzname(self, dt):
if not self._ttinfo_std:
return None
return self._find_ttinfo(dt).abbr
def __eq__(self, other):
if not isinstance(other, tzfile):
return False
return (self._trans_list == other._trans_list and
self._trans_idx == other._trans_idx and
self._ttinfo_list == other._ttinfo_list)
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "%s(%s)" % (self.__class__.__name__, repr(self._filename))
def __reduce__(self):
if not os.path.isfile(self._filename):
raise ValueError("Unpickable %s class" % self.__class__.__name__)
return (self.__class__, (self._filename,))
class tzrange(datetime.tzinfo):
def __init__(self, stdabbr, stdoffset=None,
dstabbr=None, dstoffset=None,
start=None, end=None):
global relativedelta
if not relativedelta:
from dateutil import relativedelta
self._std_abbr = stdabbr
self._dst_abbr = dstabbr
if stdoffset is not None:
self._std_offset = datetime.timedelta(seconds=stdoffset)
else:
self._std_offset = ZERO
if dstoffset is not None:
self._dst_offset = datetime.timedelta(seconds=dstoffset)
elif dstabbr and stdoffset is not None:
self._dst_offset = self._std_offset+datetime.timedelta(hours=+1)
else:
self._dst_offset = ZERO
if dstabbr and start is None:
self._start_delta = relativedelta.relativedelta(
hours=+2, month=4, day=1, weekday=relativedelta.SU(+1))
else:
self._start_delta = start
if dstabbr and end is None:
self._end_delta = relativedelta.relativedelta(
hours=+1, month=10, day=31, weekday=relativedelta.SU(-1))
else:
self._end_delta = end
def utcoffset(self, dt):
if self._isdst(dt):
return self._dst_offset
else:
return self._std_offset
def dst(self, dt):
if self._isdst(dt):
return self._dst_offset-self._std_offset
else:
return ZERO
def tzname(self, dt):
if self._isdst(dt):
return self._dst_abbr
else:
return self._std_abbr
def _isdst(self, dt):
if not self._start_delta:
return False
year = datetime.datetime(dt.year,1,1)
start = year+self._start_delta
end = year+self._end_delta
dt = dt.replace(tzinfo=None)
if start < end:
return dt >= start and dt < end
else:
return dt >= start or dt < end
def __eq__(self, other):
if not isinstance(other, tzrange):
return False
return (self._std_abbr == other._std_abbr and
self._dst_abbr == other._dst_abbr and
self._std_offset == other._std_offset and
self._dst_offset == other._dst_offset and
self._start_delta == other._start_delta and
self._end_delta == other._end_delta)
def __ne__(self, other):
return not self.__eq__(other)
def __repr__(self):
return "%s(...)" % self.__class__.__name__
__reduce__ = object.__reduce__
class tzstr(tzrange):
def __init__(self, s):
global parser
if not parser:
from dateutil import parser
self._s = s
res = parser._parsetz(s)
if res is None:
raise ValueError("unknown string format")
# Here we break the compatibility with the TZ variable handling.
# GMT-3 actually *means* the timezone -3.
if res.stdabbr in ("GMT", "UTC"):
res.stdoffset *= -1
# We must initialize it first, since _delta() needs
# _std_offset and _dst_offset set. Use False in start/end
# to avoid building it two times.
tzrange.__init__(self, res.stdabbr, res.stdoffset,
res.dstabbr, res.dstoffset,
start=False, end=False)
if not res.dstabbr:
self._start_delta = None
self._end_delta = None
else:
self._start_delta = self._delta(res.start)
if self._start_delta:
self._end_delta = self._delta(res.end, isend=1)
def _delta(self, x, isend=0):
kwargs = {}
if x.month is not None:
kwargs["month"] = x.month
if x.weekday is not None:
kwargs["weekday"] = relativedelta.weekday(x.weekday, x.week)
if x.week > 0:
kwargs["day"] = 1
else:
kwargs["day"] = 31
elif x.day:
kwargs["day"] = x.day
elif x.yday is not None:
kwargs["yearday"] = x.yday
elif x.jyday is not None:
kwargs["nlyearday"] = x.jyday
if not kwargs:
# Default is to start on first sunday of april, and end
# on last sunday of october.
if not isend:
kwargs["month"] = 4
kwargs["day"] = 1
kwargs["weekday"] = relativedelta.SU(+1)
else:
kwargs["month"] = 10
kwargs["day"] = 31
kwargs["weekday"] = relativedelta.SU(-1)
if x.time is not None:
kwargs["seconds"] = x.time
else:
# Default is 2AM.
kwargs["seconds"] = 7200
if isend:
# Convert to standard time, to follow the documented way
# of working with the extra hour. See the documentation
# of the tzinfo class.
delta = self._dst_offset-self._std_offset
kwargs["seconds"] -= delta.seconds+delta.days*86400
return relativedelta.relativedelta(**kwargs)
def __repr__(self):
return "%s(%s)" % (self.__class__.__name__, repr(self._s))
class _tzicalvtzcomp:
def __init__(self, tzoffsetfrom, tzoffsetto, isdst,
tzname=None, rrule=None):
self.tzoffsetfrom = datetime.timedelta(seconds=tzoffsetfrom)
self.tzoffsetto = datetime.timedelta(seconds=tzoffsetto)
self.tzoffsetdiff = self.tzoffsetto-self.tzoffsetfrom
self.isdst = isdst
self.tzname = tzname
self.rrule = rrule
class _tzicalvtz(datetime.tzinfo):
def __init__(self, tzid, comps=[]):
self._tzid = tzid
self._comps = comps
self._cachedate = []
self._cachecomp = []
def _find_comp(self, dt):
if len(self._comps) == 1:
return self._comps[0]
dt = dt.replace(tzinfo=None)
try:
return self._cachecomp[self._cachedate.index(dt)]
except ValueError:
pass
lastcomp = None
lastcompdt = None
for comp in self._comps:
if not comp.isdst:
# Handle the extra hour in DST -> STD
compdt = comp.rrule.before(dt-comp.tzoffsetdiff, inc=True)
else:
compdt = comp.rrule.before(dt, inc=True)
if compdt and (not lastcompdt or lastcompdt < compdt):
lastcompdt = compdt
lastcomp = comp
if not lastcomp:
# RFC says nothing about what to do when a given
# time is before the first onset date. We'll look for the
# first standard component, or the first component, if
# none is found.
for comp in self._comps:
if not comp.isdst:
lastcomp = comp
break
else:
lastcomp = comp[0]
self._cachedate.insert(0, dt)
self._cachecomp.insert(0, lastcomp)
if len(self._cachedate) > 10:
self._cachedate.pop()
self._cachecomp.pop()
return lastcomp
def utcoffset(self, dt):
return self._find_comp(dt).tzoffsetto
def dst(self, dt):
comp = self._find_comp(dt)
if comp.isdst:
return comp.tzoffsetdiff
else:
return ZERO
def tzname(self, dt):
return self._find_comp(dt).tzname
def __repr__(self):
return "<tzicalvtz %s>" % repr(self._tzid)
__reduce__ = object.__reduce__
class tzical:
def __init__(self, fileobj):
global rrule
if not rrule:
from dateutil import rrule
if isinstance(fileobj, str):
self._s = fileobj
fileobj = open(fileobj)
elif hasattr(fileobj, "name"):
self._s = fileobj.name
else:
self._s = repr(fileobj)
self._vtz = {}
self._parse_rfc(fileobj.read())
def keys(self):
return list(self._vtz.keys())
def get(self, tzid=None):
if tzid is None:
keys = list(self._vtz.keys())
if len(keys) == 0:
raise ValueError("no timezones defined")
elif len(keys) > 1:
raise ValueError("more than one timezone available")
tzid = keys[0]
return self._vtz.get(tzid)
def _parse_offset(self, s):
s = s.strip()
if not s:
raise ValueError("empty offset")
if s[0] in ('+', '-'):
signal = (-1,+1)[s[0]=='+']
s = s[1:]
else:
signal = +1
if len(s) == 4:
return (int(s[:2])*3600+int(s[2:])*60)*signal
elif len(s) == 6:
return (int(s[:2])*3600+int(s[2:4])*60+int(s[4:]))*signal
else:
raise ValueError("invalid offset: "+s)
def _parse_rfc(self, s):
lines = s.splitlines()
if not lines:
raise ValueError("empty string")
# Unfold
i = 0
while i < len(lines):
line = lines[i].rstrip()
if not line:
del lines[i]
elif i > 0 and line[0] == " ":
lines[i-1] += line[1:]
del lines[i]
else:
i += 1
tzid = None
comps = []
invtz = False
comptype = None
for line in lines:
if not line:
continue
name, value = line.split(':', 1)
parms = name.split(';')
if not parms:
raise ValueError("empty property name")
name = parms[0].upper()
parms = parms[1:]
if invtz:
if name == "BEGIN":
if value in ("STANDARD", "DAYLIGHT"):
# Process component
pass
else:
raise ValueError("unknown component: "+value)
comptype = value
founddtstart = False
tzoffsetfrom = None
tzoffsetto = None
rrulelines = []
tzname = None
elif name == "END":
if value == "VTIMEZONE":
if comptype:
raise ValueError("component not closed: "+comptype)
if not tzid:
raise ValueError("mandatory TZID not found")
if not comps:
raise ValueError("at least one component is needed")
# Process vtimezone
self._vtz[tzid] = _tzicalvtz(tzid, comps)
invtz = False
elif value == comptype:
if not founddtstart:
raise ValueError("mandatory DTSTART not found")
if tzoffsetfrom is None:
raise ValueError("mandatory TZOFFSETFROM not found")
if tzoffsetto is None:
raise ValueError("mandatory TZOFFSETFROM not found")
# Process component
rr = None
if rrulelines:
rr = rrule.rrulestr("\n".join(rrulelines),
compatible=True,
ignoretz=True,
cache=True)
comp = _tzicalvtzcomp(tzoffsetfrom, tzoffsetto,
(comptype == "DAYLIGHT"),
tzname, rr)
comps.append(comp)
comptype = None
else:
raise ValueError("invalid component end: "+value)
elif comptype:
if name == "DTSTART":
rrulelines.append(line)
founddtstart = True
elif name in ("RRULE", "RDATE", "EXRULE", "EXDATE"):
rrulelines.append(line)
elif name == "TZOFFSETFROM":
if parms:
raise ValueError("unsupported %s parm: %s "%(name, parms[0]))
tzoffsetfrom = self._parse_offset(value)
elif name == "TZOFFSETTO":
if parms:
raise ValueError("unsupported TZOFFSETTO parm: "+parms[0])
tzoffsetto = self._parse_offset(value)
elif name == "TZNAME":
if parms:
raise ValueError("unsupported TZNAME parm: "+parms[0])
tzname = value
elif name == "COMMENT":
pass
else:
raise ValueError("unsupported property: "+name)
else:
if name == "TZID":
if parms:
raise ValueError("unsupported TZID parm: "+parms[0])
tzid = value
elif name in ("TZURL", "LAST-MODIFIED", "COMMENT"):
pass
else:
raise ValueError("unsupported property: "+name)
elif name == "BEGIN" and value == "VTIMEZONE":
tzid = None
comps = []
invtz = True
def __repr__(self):
return "%s(%s)" % (self.__class__.__name__, repr(self._s))
if sys.platform != "win32":
TZFILES = ["/etc/localtime", "localtime"]
TZPATHS = ["/usr/share/zoneinfo", "/usr/lib/zoneinfo", "/etc/zoneinfo"]
else:
TZFILES = []
TZPATHS = []
def gettz(name=None):
tz = None
if not name:
try:
name = os.environ["TZ"]
except KeyError:
pass
if name is None or name == ":":
for filepath in TZFILES:
if not os.path.isabs(filepath):
filename = filepath
for path in TZPATHS:
filepath = os.path.join(path, filename)
if os.path.isfile(filepath):
break
else:
continue
if os.path.isfile(filepath):
try:
tz = tzfile(filepath)
break
except (IOError, OSError, ValueError):
pass
else:
tz = tzlocal()
else:
if name.startswith(":"):
name = name[:-1]
if os.path.isabs(name):
if os.path.isfile(name):
tz = tzfile(name)
else:
tz = None
else:
for path in TZPATHS:
filepath = os.path.join(path, name)
if not os.path.isfile(filepath):
filepath = filepath.replace(' ','_')
if not os.path.isfile(filepath):
continue
try:
tz = tzfile(filepath)
break
except (IOError, OSError, ValueError):
pass
else:
tz = None
if tzwin:
try:
tz = tzwin(name)
except OSError:
pass
if not tz:
from dateutil.zoneinfo import gettz
tz = gettz(name)
if not tz:
for c in name:
# name must have at least one offset to be a tzstr
if c in "0123456789":
try:
tz = tzstr(name)
except ValueError:
pass
break
else:
if name in ("GMT", "UTC"):
tz = tzutc()
elif name in time.tzname:
tz = tzlocal()
return tz
# vim:ts=4:sw=4:et
How to Test Gmail Logger
- Enter the following command to test Gmail Logger:
python log_inbox.py
How to View Exported Data from Gmail Logger in JSON File
Once you have logged the Gmail inbox metadata using Gmail Logger, the next step is to view and analyze the logged data. In this section, we’ll explore how to view the exported Gmail data and how to analyze and process the metadata to gain valuable insights.
How to Locate the JSON File
The Python script saves the JSON file with a filename based on the current date and time. Look for a file with a .json extension in the same directory where the script was executed.
How to Open the JSON File
Right-click on the JSON file and choose an option like “Open With” or “Open” from the context menu. Select a text editor or JSON viewer application from the available options.
- If you choose a text editor (e.g., Notepad, Sublime Text, Visual Studio Code), the JSON file will open as plain text, and you can read its contents directly.
- If you choose a JSON viewer or specialized JSON editor (e.g., JSONView extension in web browsers, JSONedit), the file will be displayed in a structured format, making it easier to navigate and explore the data.
How to Navigate and Explore the JSON Data
Once the JSON file is open, you can view the data structure and its contents. JSON files are typically organized in a hierarchical format, with objects represented by curly braces {} and arrays represented by square brackets [].
- You can expand or collapse nested objects or arrays to explore the data structure.
- Clicking on individual elements will reveal their values or expand any sub-objects or sub-arrays they contain.
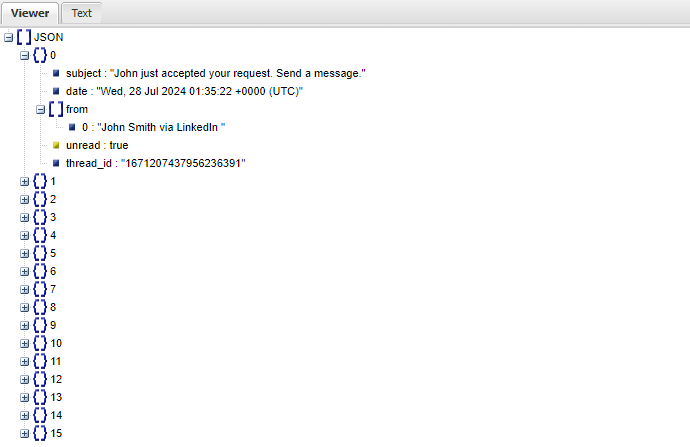
How to Interpret the JSON Data
The structure and content of the JSON data depend on the logic and implementation of the Gmail Logger script. Each entry in the JSON file represents summarized information about a Gmail thread, including properties like subject, date, sender, and unread status.
- You can interpret and analyze the JSON data based on its key-value pairs and nested structures.
- Take note of the available properties and their values to gain insights into the Gmail thread information.
Analyzing and Processing the Metadata for Insights
With the logged data exported to a JSON file, you can now analyze and process the metadata to derive valuable insights. Here are a few approaches you can take:
Statistical Analysis
Utilize statistical techniques to uncover patterns, trends, or correlations within the logged metadata. For example, you can calculate email response times, identify frequent senders or recipients, or analyze the distribution of email subjects or labels.
Data Visualization
Visualize the metadata using charts, graphs, or other visual representations to gain a better understanding of email patterns or trends. Visualizations can help identify outliers, cluster similar emails, or showcase email activity over time.
Natural Language Processing (NLP)
Apply NLP techniques to analyze the email content, such as sentiment analysis, keyword extraction, or topic modeling. This can provide insights into the tone of email conversations, prevalent topics, or emerging themes.
Automation and Integration
Integrate the logged data into your existing workflows or applications to automate processes or trigger actions based on specific conditions. For example, you can automatically categorize emails based on logged metadata, generate reports, or initiate follow-up tasks.
By analyzing and processing the logged metadata, you can unlock valuable insights, improve productivity, and gain a deeper understanding of your email communication patterns.
In the following sections, we’ll discuss best practices, tips, and real-world use cases to help you make the most of the logged Gmail inbox metadata and leverage it for various purposes.
Gmail Logger Best Practices and Tips
When using Gmail Logger to log Gmail inbox metadata, it’s important to follow best practices and implement certain tips to ensure data privacy, maintain security, and optimize performance and efficiency. This section covers some key practices and tips to consider.
Ensuring Data Privacy and Security
Secure Credentials
Keep the credentials file containing your client ID and client secret secure. Avoid sharing it publicly or storing it in insecure locations. Treat it as sensitive information to prevent unauthorized access to your Gmail account.
Limit Access
Grant access permissions to Gmail Logger only to the necessary Google account(s) and scopes required for logging the required metadata. Minimize access privileges to reduce potential risks.
Protect Exported Data
When exporting the logged data to a JSON file, ensure that the destination location is secure and accessible only to authorized individuals. Consider encrypting the exported file to provide an additional layer of protection.
Compliance with Regulations
If you’re logging sensitive or personally identifiable information (PII), ensure compliance with applicable data protection and privacy regulations, such as GDPR (General Data Protection Regulation) or CCPA (California Consumer Privacy Act).
Optimizing Performance and Efficiency for Gmail Logger
Logging Frequency
Determine an appropriate logging frequency based on your needs and the volume of emails. Consider factors such as the frequency of new emails, the amount of metadata to be logged, and the impact on system resources. Logging too frequently may overload the system, while logging too infrequently may result in incomplete or outdated data.
Error Handling
Implement robust error handling mechanisms in the Gmail Logger script. Handle potential errors gracefully, provide informative error messages, and consider implementing retry mechanisms for intermittent errors to ensure reliable logging.
Logging Filters
Optimize your email filtering criteria to capture the most relevant emails and minimize unnecessary logging. Refine your filters based on labels, date ranges, or keywords to focus on the data that is most important for your analysis or organization.
Resource Management
Monitor system resources, such as CPU usage and memory consumption, while running Gmail Logger. Optimize resource allocation to ensure the logging process does not impact the overall system performance.
By adhering to these best practices and implementing the suggested tips, you can ensure the privacy and security of your data while maximizing the performance and efficiency of the Gmail Logger tool.
In the final section, we’ll explore real-world use cases where Gmail Logger can be applied to various scenarios, providing insights and value to individuals and organizations.
Gmail Logger Use Cases and Examples
Gmail Logger offers a wide range of use cases and can be applied to various scenarios where logging Gmail inbox metadata is valuable. This section highlights some common use cases and examples to inspire your application of Gmail Logger.
Logging Emails for Email Analysis Projects
Gmail Logger can be a powerful tool for email analysis projects, providing insights into email communication patterns, trends, and behaviors. Here are a few examples:
Email Response Time Analysis
By logging email timestamps and analyzing response times, you can measure and optimize email communication efficiency. Identify bottlenecks, improve response rates, or evaluate workload distribution among team members.
Email Categorization and Labeling
Log email labels and use the metadata to categorize and label emails automatically. This can help streamline email organization, prioritize important messages, or create custom workflows based on specific labels.
Email Activity Tracking
Analyze email frequency, volume, and patterns over time. Gain insights into peak email periods, email trends across different time zones or departments, or identify communication gaps.
Integrating Gmail Logger with Other Tools and Workflows
Gmail Logger can seamlessly integrate with other tools and workflows to enhance productivity and automate processes. Consider the following examples:
CRM Integration
Integrate the logged metadata with Customer Relationship Management (CRM) systems. Link emails to customer profiles, track communication history, or trigger automated actions based on email metadata.
Project Management Integration
Connect Gmail Logger with project management tools to log and track email communication related to specific projects or tasks. Improve collaboration, monitor progress, and ensure all relevant emails are logged within project contexts.
Reporting and Analytics
Export the logged data to analytics platforms or data visualization tools to generate insightful reports and visual representations. Identify trends, measure email performance, or derive actionable insights for decision-making.
These examples demonstrate the versatility of Gmail Logger and its potential to add value to various domains, from personal productivity to team collaboration and data-driven decision-making.
In conclusion, Gmail Logger empowers you to log Gmail inbox metadata, customize logging options, and leverage the data for analysis and integration with other tools and workflows. By applying Gmail Logger creatively, you can unlock the full potential of your Gmail inbox data and enhance your email management practices.